Abstract
Synthesizing performing guitar sound is a highly challenging task due to the polyphony and high variability in expression. Recently, deep generative models have shown promising results in synthesizing expressive polyphonic instrument sounds given music score input. They usually use a generic MIDI input representation to accommodate multiple types of instruments. In this work, we propose an expressive acoustic guitar sound synthesis model with a customized input representation to the instrument, which we call guitarroll. We implement the proposed approach with a diffusion-based model based on outpainting which can generate audio with long-term consistency. To overcome the lack of MIDI/audio-paired datasets, we used not only an existing guitar dataset but also collected data from a high quality sample-based guitar synthesizer. Through quantitative and qualitative evaluations, we show that our proposed model has higher audio quality than the baseline model and generates more realistic timbre sounds than the previous leading work.
Model Overview
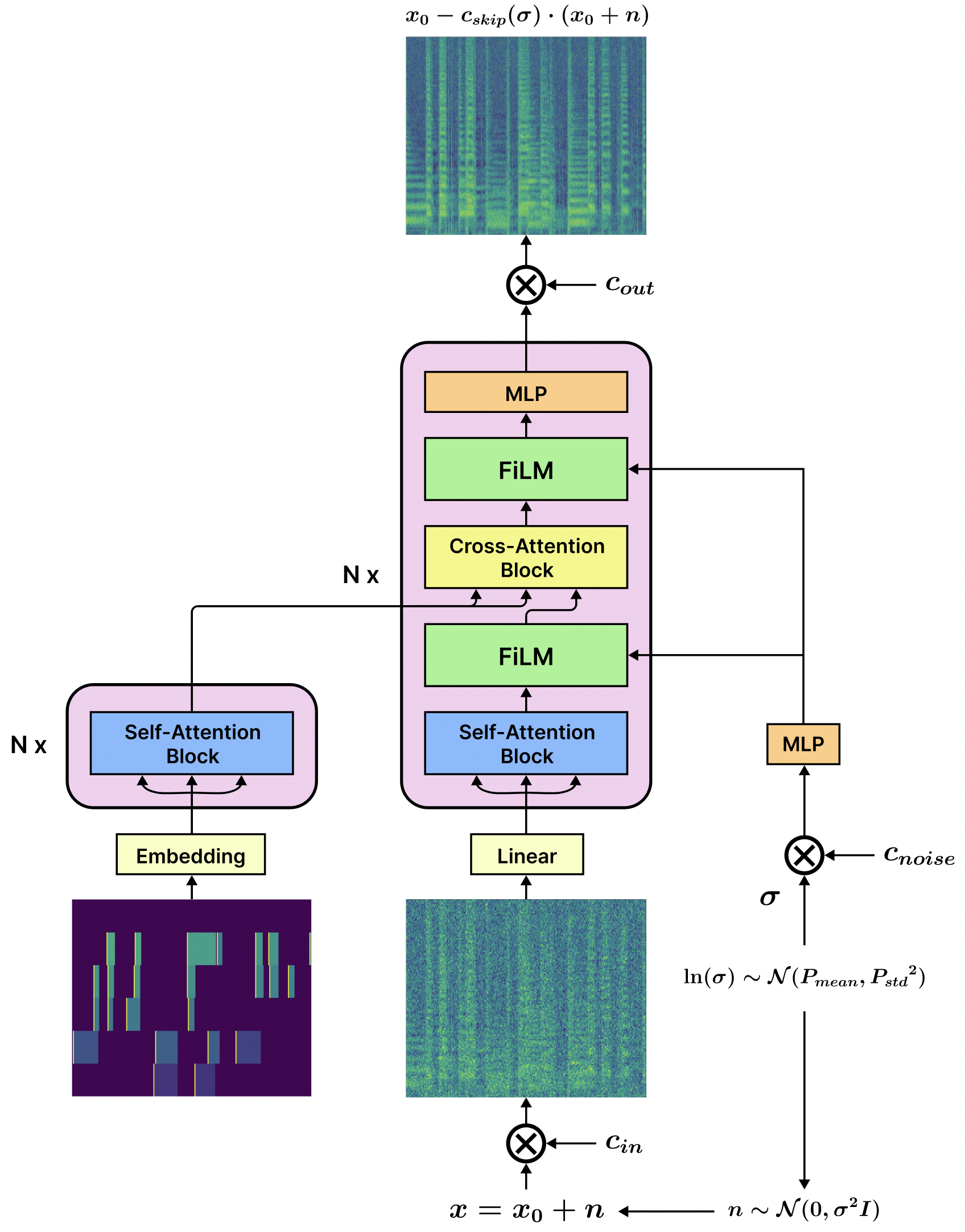
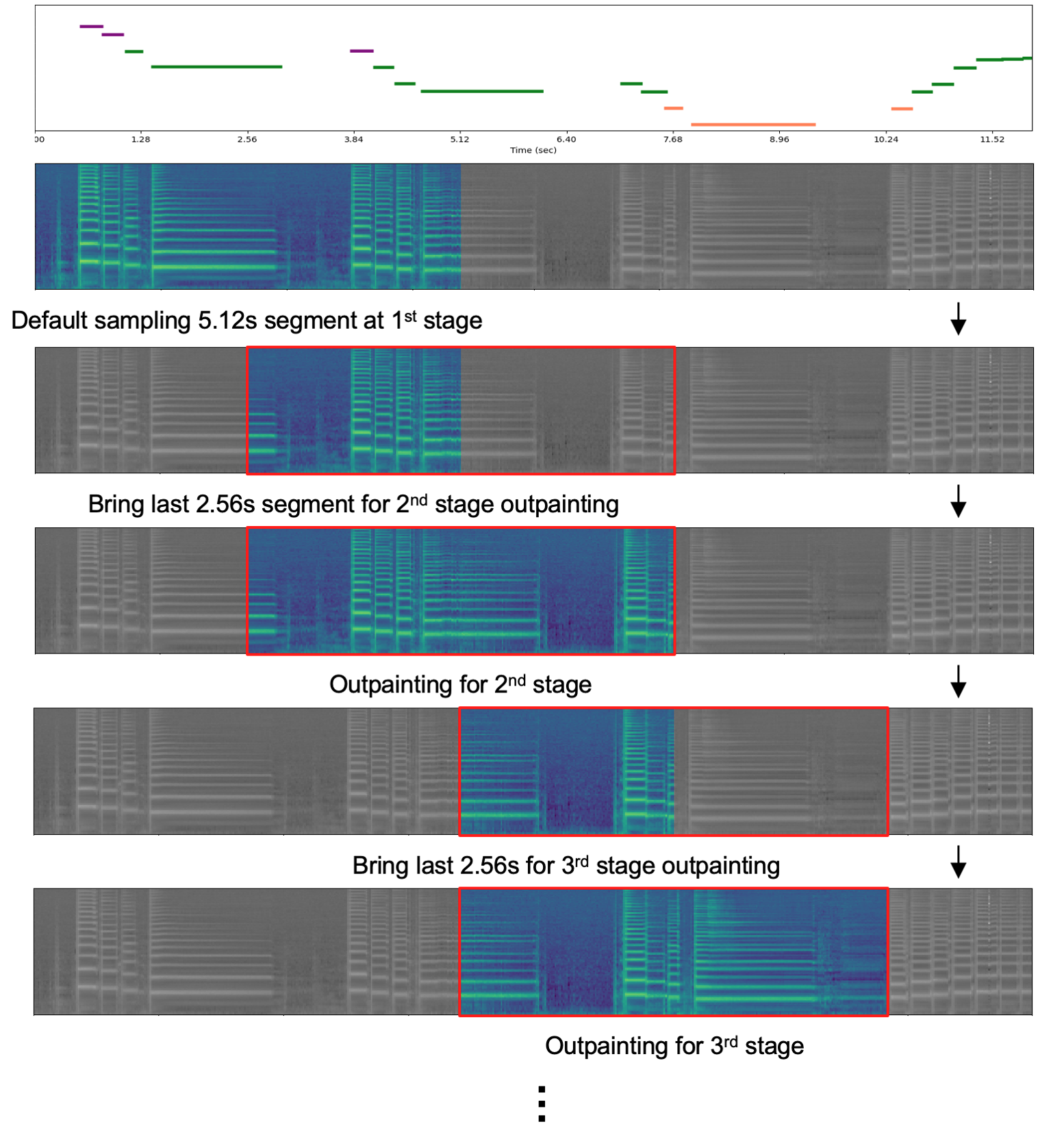
Model Architecture Outpainting Procedure
Audio examples
Sample 1 (comp)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo
Sample 2 (comp)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo
Sample 3 (comp)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo
Sample 4 (solo)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo
Sample 5 (solo)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo
Sample 6 (solo)
Ground-truth BaselineFT
OutpaintingFT Hawthorne Demo